

From Blur to Clarity: Understanding Aggregates, Anti-patterns, and Their Fixes in DDD

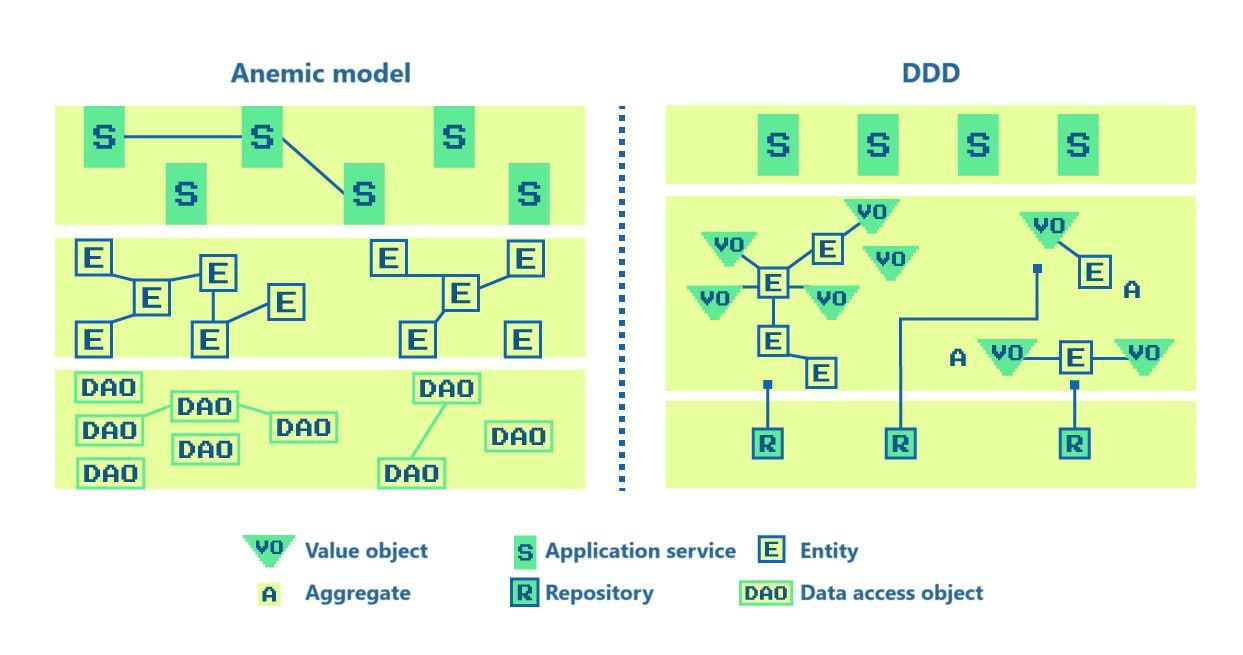
Domain-Driven Design distinguishes between strategic and tactical patterns. For example, the first are the Ubiquitous Language, and the second are Aggregates. I have heard many times from my colleagues that everything is clear with strategic patterns, but when it comes to moving to the tactical level (close to code), it's all just a blur. It leads to incorrect technical solutions that cannot be compensated even with the right attitude and closeness to the business. Mastering tactical patterns, especially Aggregates, is critical to project success. This is because Aggregates encapsulate almost all business logic; they are the basis of your application. In this article I will tell you about Aggregates, how they can help and why it is important to master them. To begin, let's discuss anti-patterns a bit...
Anti-patterns
Successful decisions are fixed as patterns. Unsuccessful solutions that developers use again and again become fixed as anti-patterns.
Anemic model
This is the first anti-pattern that I encounter all the time. A typical anemic model looks like a set of classes that fairly accurately convey the state of real-world objects. But these classes have no behavior unless you count a bunch of getters and setters as behavior. Filling out the fields in such a model occurs in the domain services layer. In fact, the models themselves do not own their fields.
//typical anemic model
public class Order
{
public UUId Id {get; set;}
public Product[] Items {get; set;}
public decimal TotalPrice {get; set;}
public Tax[] Taxes {get; set;}
public Address DeliveryAddress {get; set;}
public string Phone {get; set;}
}Disadvantages of the model.
The class has no invariants. An object is usually created by a parameterless constructor, not necessarily in a consistent state. During the lifetime of an instance, the fields may change in different places and a meaningful state cannot be guaranteed. For example, you might forget to set the correct value TotalPrice when recalculating taxes, changing address or list of products.
Juggling. Typically, the domain services layer is represented by several services and an instance of the class is transferred between services. Each service changes part of the object's state. For example, there is Order and OrderService creates an instance in some state, then CalculationService fills in prices, discounts, taxes, and some DeliveryService adds delivery information. Some services can update object fields, while others can only read them. But we still get high connectivity of services through such objects and low cohesion (we will return to these terms later).
How to fix it?
If there are a lot of anemic models in the project, start with “cleaning”: remove public setters; remove parameterless constructors. I note that it will not be possible to change it in one fell swoop. This is a long refactoring process. It's not worth transitioning an anemic model into aggregates in the style of the Big Bang.
Before introducing new logic at the application service level, think about the reasons - whether this logic can be placed inside a class. There is an excellent example of the refactoring from an anemic model to a domain rich one from Kamil Grzybek.

Using Anemic Models to DTO is absolutely correct.
Universal model
The second anti-pattern comes from excessive reuse of classes and modules and an attempt to build universal classes that describe all possible aspects of real-world objects. For example, let's return to our Order.

As the system evolves, the object receives fields to meet any new requirements. Such an object contains all the cases that can happen with an Order in our system. It turns out to be such an “Escher ladder”: each part seems to be normal and useful, but everything together is already difficult to perceive.

Disadvantages of the anti-pattern.
Only part of the model is used each time. The object is large, our services and repositories fill only part of the fields, and the rest may remain uninitialized, and the object may end up in an inconsistent state.
It's not clear where to wait Null Reference Exception. (NullPointerException, AttributeError: 'NoneType' object has no attribute and so on.). From the previous paragraph it follows that you can easily meet null. Without viewing the code of services and repositories, you cannot say which fields in a given flow are filled in and which are not. The worst thing is that later someone might “optimize” the application a little and stop filling out some of the fields. Static usage search becomes a useless tool, since you have to go directly through the code.
There is a lot of unnecessary data in objects. For example, you get the order history for a user, and each element of this array will be a full instance with taxes, products and ingredients. Extra fields can require significant additional costs in memory, traffic, and CPU if such an object is intensively used in a loaded service.
There are no boundaries and no contract. The worst thing is that the boundaries of such models begin to float. Due to the overabundance of details, it is difficult for the developer to make good decisions about the appropriateness of a new field in an object, about the appropriate naming.
How to fix it?
Don't try to build universal models.
DDD uses an approach of partitioning models into Bounded Contexts. Several concise Order models do not violate the DRY principle. You shouldn't repeat yourself in behavior, and don't be afraid to repeat yourself in data.
Let's move on to Aggregates.
Aggregate
When using DDD, it is common to divide our domain classes into Entities and Value objects. They differ significantly from each other, for example, entities have a history, and Value Objects have a zero life cycle. The most important difference between them is the rules of identity. You can read more in the article of Vladimir Khorikov «Entity vs Value Object: complete list of differences».
An aggregate is a cluster of Entities and Value Objects, which is perceived from the outside as a single whole.
All these entities are accessible only through the Aggregate Root. It sounds simple, but it is not clear. I’ll show you with an example - let’s take our Order, which, in addition to other fields, has Taxes and Products.
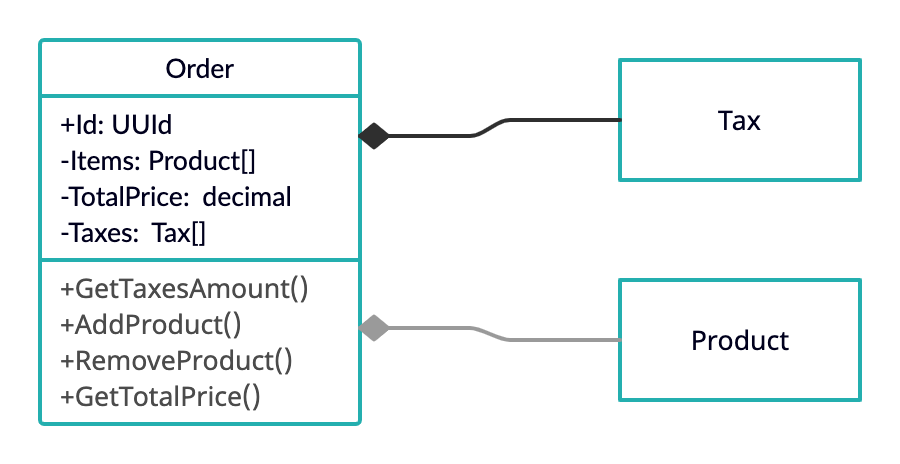
What can we do:
Somehow get the entire cluster by the Id of the root of the Aggregate, or another set of attributes that determine the identity.
Use public methods of the Aggregate root to change state, including internal entities.
Avoid:
Receive Tax/Product instances directly, bypassing the Order entity.
Expose the structure of the unit to the outside. It’s better to just expose a set of methods and leave the internal structure unknown.
//Sometimes it is necessary to set part of an aggregate, in which case you can set it as read-only fields
private readonly List<OrderItem> _orderItems;
public IReadOnlyCollection<OrderItem> OrderItems => _orderItems;Thus, external consumers do not know anything about the structure of our unit (we have an array under the hood or a dictionary - it doesn’t matter!). Such an object cannot be brought into an inconsistent state. In the case of an anemic model, we can forget to change interconnected fields synchronously at any time, for example,Items and TotalPrice. Using aggregates, we write business logic in one place, we can set explicit class invariants, and write a test.
// simple example of a unit Order
public class Order
{
public UUId Id { get; }
private List<Product> _items;
private decimal _totalPrice;
private List<Tax> _taxes;
public Order(UUId id)
{
Id = id;
_items = new List<Product>();
_totalPrice = 0;
_taxes = new List<Tax>();
}
public void AddProduct(Product product)
{
// The unit itself can determine whether such a product can be added
if (!CanAddProduct(product))
{
return;
}
_items.Add(product);
// recalculate taxes and total cost
RecalculateTaxesAndTotalPrice();
}
public decimal GetTaxesAmount()
{
return _taxes.Sum(x => x.Amount);
}
private void RecalculateTaxesAndTotalPrice()
{
_taxes = ...
_totalPrice = _items.Sum(x => x.Price) + _taxes.Sum(x=>x.Amount);
}
private bool CanAddProduct(Product product)
{
//some checks
return true;
}
}Rulemaking
It would seem - write code and don’t pay attention to anyone. But we also have our own laws. They, of course, are not as mandatory as the law of conservation of energy, but it is better to know them.
Law of Demeter
Law of Demeter or "Don't talk to strangers." On the wiki this law is explained as follows:
So the code a.b.Method() violates the Law of Demeter, and the code a.Method() is correct.
Wait! But our units require this type of coding. A correct unit does not expose the behavior of its parts, only its own. Strangers will not pass! For example, obtaining the tax amount will be done through the root method.
private Tax[] _taxes;
public Money GetTaxesAmount()
{
return _taxes.Sum(x=>x.Amount);
}The less you expose, the easier it is to refactor and evolve. After all, there is no need to change consumers. This is how we reduce the Coupling of our code.
Constantine's Law
A structure is stable if cohesion is strong and coupling is low.
What is Coupling? How does this relate to Cohesion? Coupling is a measure of the interdependence of various classes and modules with each other. When using universal anemic models and a service layer, we often get extensive use of domain classes within Services. Which in turn leads to increased Coupling.

When using aggregates, we hide the information (put the minimum contract outside) and transfer all the logic inside the aggregate. We no longer need to transfer our objects between services - Coupling is reduced.
Cohesion is a measure of how much the tasks of one software module require the use of other modules. One of the advantages of a strong Cohesion is the localization of changes for a new feature. In the case of an aggregate, all business logic is usually localized in the aggregate itself, which is how we get Strong Cohesion.
As you can see, the use of aggregates allows you to obtain Low Coupling and Strong Cohesion.
Conclusion
Aggregate is the most important pattern in the Domain-Driven Design.
When using it you get many benefits:
Low Coupling.
Strong Cohesion.
Excellent testability: you write state tests with no mocks.
Clear contract and class invariants.
The topic of aggregates, of course, is not exhausted by this article. In the following articles, I will talk about more complex topics: how to choose an Aggregate, how they interact, and I will touch on transactional boundaries.
I suggest delving into:
Vladimir Khorikov's blog, especially the article Domain model purity vs. domain model completeness.
There is also a course by Vladimir Khorikov on Pluralsight and source code for the course.
The refactoring experience is described in the mentioned example from Kamil Grzybek, in the article Refactoring from anemic model to DDD.